Les LLM sont-ils déjà dépassés ?
Depuis fin 2022, l’intelligence artificielle s’est imposée comme l’un des grands thèmes structurants de la tech mondiale. Des outils comme ChatGPT, Claude ou Gemini ont profondément transformé les usages, en rendant accessibles au grand public des capacités autrefois réservées à la recherche. Cette révolution repose sur une même brique technologique, les grands modèles de langage, qui ont concentré l’essentiel des investissements ces dernières années.
Pourtant, à mesure que leur adoption progresse, un débat s’installe sur leurs limites structurelles et sur la trajectoire à long terme de cette technologie.
Une puissance impressionnante, mais de plus en plus coûteuse
Les LLM ont démontré une efficacité remarquable pour produire du texte, écrire du code ou synthétiser de l’information, grâce à une approche consistant à analyser des volumes massifs de données afin d’anticiper la suite la plus probable d’une phrase. Ce fonctionnement, qui peut paraître simple dans son principe, nécessite en réalité des moyens considérables.
L’entraînement de ces modèles mobilise des infrastructures gigantesques et une puissance de calcul en constante augmentation, au point que certains acteurs envisagent des investissements dépassant 1 000 milliards de dollars sur plusieurs années. Cette intensité capitalistique, rarement observée dans l’histoire de la tech, pose inévitablement la question de la rentabilité à terme, d’autant qu’elle s’accompagne d’une consommation énergétique en forte hausse.
Dans ce contexte, chaque gain de performance devient plus difficile à obtenir, car il repose sur des ressources toujours plus importantes pour des améliorations de plus en plus marginales.
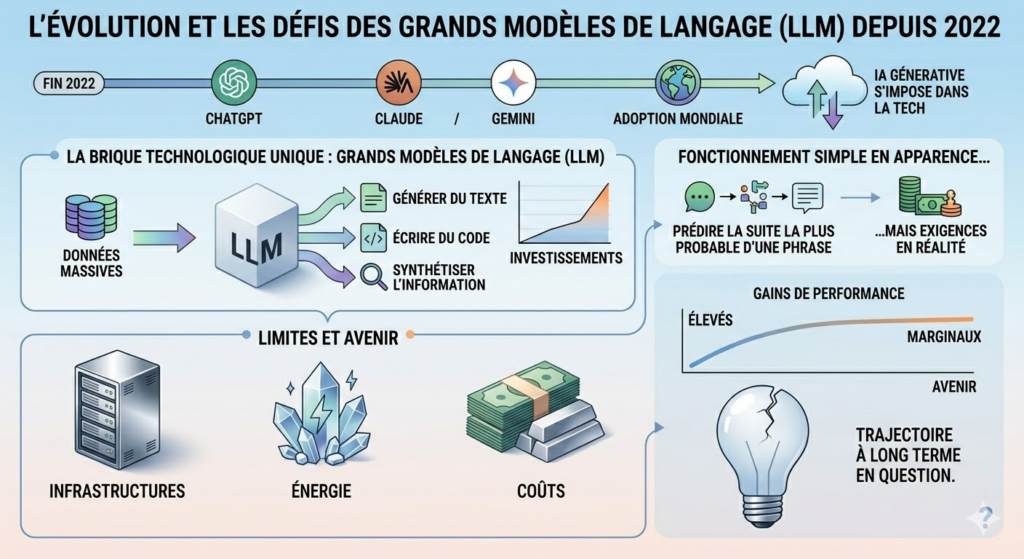
Des limites techniques qui apparaissent progressivement
Au-delà de ces contraintes économiques, les limites intrinsèques des LLM deviennent plus visibles à mesure que les usages se généralisent. Ces modèles excellent dans la manipulation du langage, mais restent fondamentalement probabilistes, ce qui signifie qu’ils ne disposent pas d’une véritable compréhension du monde réel.
Cette absence de représentation concrète se traduit par des erreurs, des incohérences ou des réponses parfois peu fiables dans des situations complexes, en particulier lorsqu’il s’agit de raisonner ou d’anticiper des enchaînements d’événements.
Par ailleurs, plusieurs travaux récents suggèrent que les progrès ralentissent, car l’augmentation du nombre de paramètres ou de données n’entraîne plus les gains spectaculaires observés lors des premières générations de modèles. L’industrie se heurte ainsi à une forme de plafond technologique qui pousse à repenser les approches actuelles.
Le retour de modèles plus efficaces et mieux ciblés
Face à ces contraintes, les entreprises s’orientent progressivement vers des modèles plus compacts et spécialisés. Les SLM, ou small language models, répondent à cette logique en étant entraînés sur des données spécifiques, avec des besoins en calcul plus faibles.
Cette approche permet non seulement de réduire les coûts, mais aussi d’améliorer la fiabilité sur des cas d’usage précis, notamment dans des environnements où la confidentialité des données est un enjeu central. En parallèle, certaines équipes travaillent sur des architectures hybrides, combinant les capacités d’apprentissage statistique avec des règles logiques plus strictes, afin de sécuriser les résultats dans des secteurs sensibles comme la finance ou la santé.
Les “world models”, une nouvelle frontière
Dans ce paysage en mutation, une approche plus radicale émerge avec les “world models”, défendus notamment par Yann LeCun. L’ambition est de dépasser la simple manipulation du langage pour construire des modèles capables de représenter le monde réel dans toute sa complexité.
Contrairement aux LLM, ces systèmes s’appuient sur des données multimodales, intégrant images, sons et vidéos, afin de comprendre les interactions physiques et d’anticiper les conséquences d’une action. L’objectif n’est plus seulement de prédire, mais de simuler, ce qui rapproche davantage ces modèles du fonctionnement humain.
L’intérêt croissant pour cette approche se matérialise déjà par des investissements significatifs, comme en témoigne la levée de plus d’un milliard de dollars de la start-up AMI, fondée par Yann LeCun, qui entend ouvrir une nouvelle phase dans le développement de l’intelligence artificielle.
Une évolution progressive plutôt qu’un basculement brutal
Pour autant, il serait excessif de considérer que les LLM sont déjà dépassés. Leur adoption reste encore partielle dans de nombreuses entreprises, et leur potentiel économique demeure important à court terme, en particulier pour les usages liés au traitement du langage.
Nous assistons davantage à une phase de transition, au cours de laquelle les LLM devraient continuer à jouer un rôle central tout en s’intégrant progressivement dans des systèmes plus complexes et complémentaires.
Dans cette perspective, l’enjeu pour les acteurs du secteur ne réside plus uniquement dans la taille des modèles ou dans la quantité de données mobilisées, mais dans la capacité à concevoir de nouvelles architectures capables de mieux appréhender le réel.
Pour les investisseurs comme pour les entreprises, cette évolution impose une lecture plus nuancée du marché, car la prochaine rupture pourrait ne pas venir d’un modèle plus puissant, mais d’une manière différente de penser l’intelligence artificielle.
Cette newsletter, préparée par EuroLand Corporate à titre purement informatif, ne constitue ni une offre, ni une invitation à acheter ou souscrire des titres.Les opinions et estimations qu’elle contient reflètent le jugement d’EuroLand Corporate à la date de publication et peuvent être modifiées sans préavis. Leur exactitude ou exhaustivité n’est pas garantie. EuroLand Corporate, ses dirigeants ou salariés peuvent détenir des titres de la société mentionnée, sans que cela ne remette en cause leur indépendance. Chaque investisseur doit se forger sa propre opinion sur la pertinence d’un investissement, en tenant compte de sa situation personnelle.
